
Meilisearchとは
フランスのMeilisearch社が開発したRust製の全文検索エンジンです。導入が簡単で設定などもシンプル。さらに、高速です。
日本語のトークナイズ(単語分割)にも対応しており、開発者体験が良いことで近年注目されている全文検索エンジンだそうです。また、全文検索以外にも位置情報検索やベクトル検索などのセマンティック検索などにも対応しています。
SolrやElasticsearchほど大規模向けではないが、実装が簡単でサクッと導入できるみたいな立ち位置でしょうか。数億規模のデータを扱わないのであれば、Melisearchで十分な気がします。
公式サイトを貼っておきます。
Laravel Scoutとは
Laravel Scoutは、Eloquentモデルに「全文検索」機能を簡単に追加するためのLaravel公式パッケージです。データベースの「LIKE検索」では限界がある複雑な検索を、直感的なコードで実装できます。
公式ドキュメントは以下です。
https://readouble.com/laravel/12.x/ja/scout.html
主な特徴とメリットをまとめてみました。
| 特徴 | メリット |
|---|---|
| 自動同期 | データを保存・更新すると、検索エンジン側のデータも自動で最新に保たれます。 |
| ドライバ形式 | 検索エンジン(Algolia, Meilisearch, Databaseなど)を自由に切り替え可能です。 |
| 読みやすい記述 | Model::search('キーワード')->get() などシンプルな記法で検索できます。 |
| データベース負荷の軽減 | 検索処理を外部エンジンに任せることで、DB本体の負荷を抑えられます。 |
ブログの検索窓をサクッと実装したいなど小規模な場合は「Database」ドライバで十分です。より高速・高機能な検索機能を目指すなら「Meilisearch」や「Algolia」を選ぶのが王道だそうです。ごちゃごちゃしたSQLを書きたくない人はおすすめのパッケージです。
事前準備
まずは、プロジェクトの作成やデータ準備から始めていきます。先にMeilisearchの導入を見たい方はこのステップは飛ばしてください。
今回はDocker ComposeでMySQLとMeilisearchサーバーを用意していきます。
docker composeファイル作成
docker composeファイルを以下の通り作成します。
# docker-compose.yml
services: # MySQL データベース
mysql:
image: mysql:8.0
container_name: mysql-dev
ports:
- "3306:3306"
environment:
MYSQL_DATABASE: ms_db
MYSQL_USER: db_user
MYSQL_PASSWORD: db_pass
MYSQL_ROOT_PASSWORD: root_pass
volumes:
- mysql_data:/var/lib/mysql
# Meilisearch 検索エンジン
meilisearch:
image: getmeili/meilisearch:latest
container_name: meilisearch-dev
ports:
- "7700:7700"
environment:
MEILI_MASTER_KEY: masterKey
volumes:
- meili_data:/data.ms
volumes:
mysql_data:
meili_data:
先に.envファイルを更新しておきます。
DB_CONNECTION=mysql
DB_HOST=127.0.0.1
DB_PORT=3306
DB_DATABASE=ms_db
DB_USERNAME=db_user
DB_PASSWORD=db_pass
Dockerの起動と確認を行います。
$ docker compose up -d
$ docker ps
migrationファイルの作成
migrationファイルを作成します。今回はpostsテーブルを作成しておきます。
$ php artisan make:model Post -m
migrationファイルは以下のように編集します。
public function up(): void
{
Schema::create('posts', function (Blueprint $table) {
$table->id();
$table->string('title');
$table->text('content');
$table->timestamps();
});
}
データベースに反映します。
$ php artisan migrate
PostFactoryクラスの作成
PostFactoryクラスを作成します。
$ php artisan make:factory PostFactory
PostFactoryクラスを以下のように編集します。
**public function definition(): array
{
return [
'title' => fake()->realText(20), // 20文字程度の日本語タイトル
'content' => fake()->realText(200), // 200文字程度の日本語本文
];
}**
Post ModelにHasFactoryトレイトをuseしておくのを忘れないようにしましょう。
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
use Illuminate\Database\Eloquent\Factories\HasFactory;
class Post extends Model
{
use HasFactory;
...
.env も更新しておきます。
APP_FAKER_LOCALE=ja_JP
では、Factoryを実行します。
php artisan tinker
# 実行
> App\Models\Post::factory()->count(100)->create();
これで事前準備は完了です。
Laravel ScoutでMeilisearch全文検索エンジンを使ってみる
ここからが本題です。Laravel Scoutパッケージを導入してMeilisearchエンジンを使っていきましょう。
Laravel Scout導入
まずはLaravel Scoutパッケージを導入します。
$ composer require laravel/scout
次にMeilisearch用のクライアントを導入します。
$ composer require meilisearch/meilisearch-php http-interop/http-factory-guzzle
設定ファイルを生成します。
$ php artisan vendor:publish --provider="Laravel\Scout\ScoutServiceProvider"
.envファイルに以下を追記します。
SCOUT_DRIVER=meilisearch
MEILISEARCH_HOST=http://127.0.0.1:7700
これでScoutのドライバーがMeilisearchに設定されたことになります。
Searchableトレイトの追加
今回の全文検索対象であるPost Modelに対してSearchableトレイトをuseします。
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
use Illuminate\Database\Eloquent\Factories\HasFactory;
use Laravel\Scout\Searchable;
class Post extends Model
{
use HasFactory;
use Searchable;
/**
* 検索インデックスに保存するデータのカスタマイズ
*/
public function toSearchableArray(): array
{
return [
'id' => (int) $this->id,
'title' => $this->title,
'content' => $this->content,
];
}
}
toSearchableArray() メソッドでMeilisearchエンジンにインデックスしたいデータを定義しています。
Meilisearchエンジンへのデータインポート
Meilisearchエンジンへデータをインポートします。以下のコマンドからインポートが可能です。
$ php artisan scout:import "App\Models\Post"
Meilisearch\Exceptions\ApiException
The Authorization header is missing. It must use the bearer authorization method.
おっと!エラーになってしまいましたね。
どうやら、Docker Composeに記述した以下が原因になっているようです。
environment:
MEILI_MASTER_KEY: masterKey
マスターキーありでMeilisearchコンテナを起動していたため、キーを要求されてしまっていたようです。通常はマスターキーが必要となりますが、今回は開発環境のみの検証なのでキーなしで起動してみます。
# environment:
# MEILI_MASTER_KEY: masterKey
更新後にDockerコンテナを再起動してから、再度インポートします。
$ php artisan scout:import "App\Models\Post"
Imported [App\Models\Post] models up to ID: 100
All [App\Models\Post] records have been imported.
成功しました。
Meilisearchはマスターキーなしでも動作するように親切な設計がされていますが、本番環境などでは必ずセットするようにしましょう。キーは推測されにくい長い文字列を自分で生成してセットします。
以下のURLから実際にデータがインポートできたかを確認できます。
http://localhost:7700
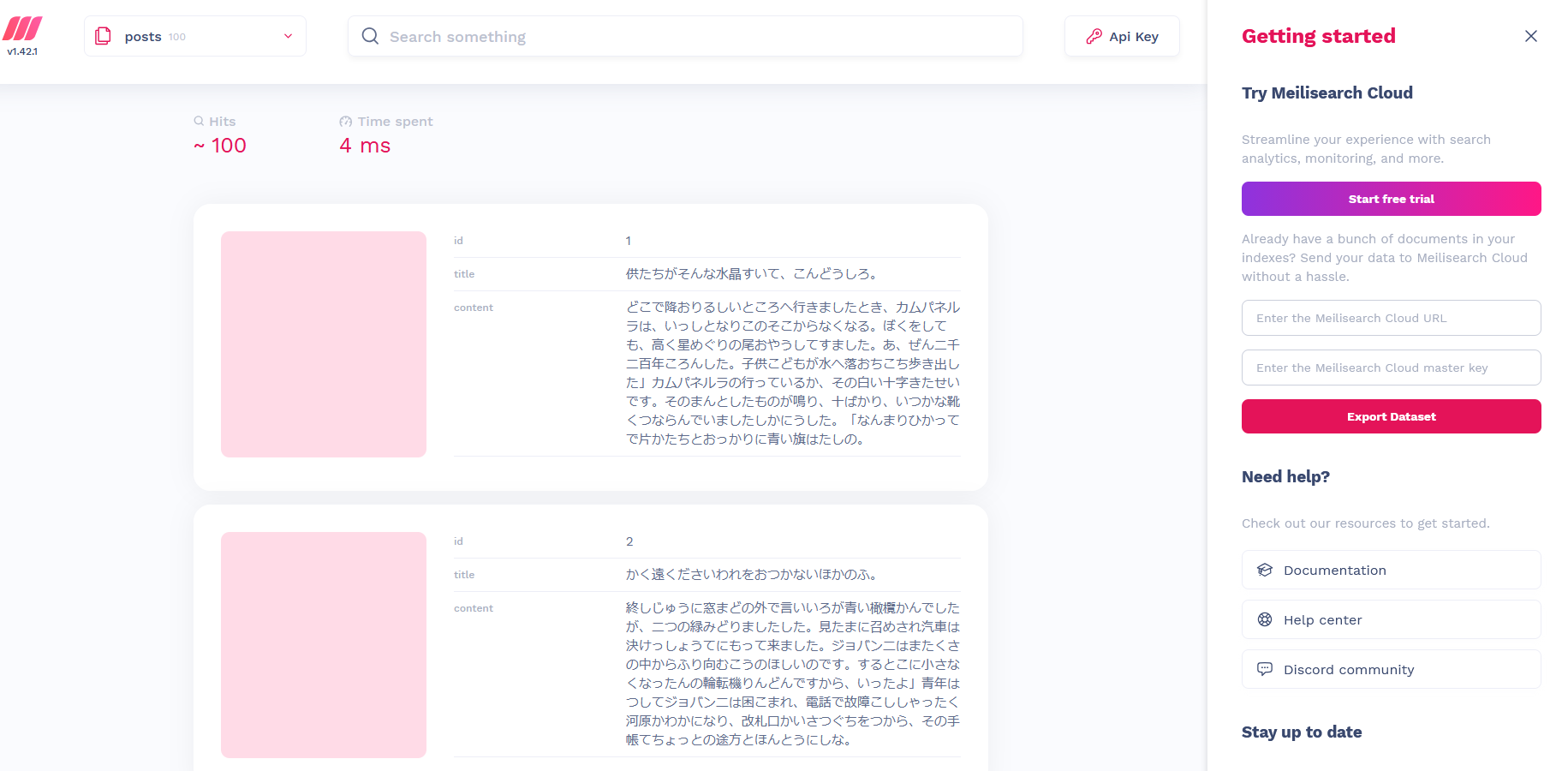
検索処理の作成
簡易的な検索処理を作成してみます。
// routes/web.php
Route::get('/posts/{keyword}', function ($keyword) {
$posts = App\Models\Post::search($keyword)->get();
return $posts;
});
検索処理は非常にシンプルで可読性が高いですね!
それでは、実際にアクセスして動作確認していきましょう。
$ php artisan serve
以下にアクセスしてみます。
http://localhost:8000/posts/リチウム

データ取得できていそうです。
速度検証
せっかくなので、通常のLIKE検索と比較するとどれくらいの検索速度になるかを検証してみたいと思います。具体的なソースコードはここでは解説しません。
まずは、postsのデータ100件で検証してみます。
| 検索方法 | 検索キーワード | ヒット件数(件) | 検索時間(ms) |
|---|---|---|---|
| LIKE検索 | リチウム | 2 | 1.42 |
| LIKE検索 | 水晶 | 7 | 1.39 |
| LIKE検索 | 水 | 26 | 11.76 |
| Meilisearch検索 | リチウム | 2 | 77.08 |
| Meilisearch検索 | 水晶 | 7 | 5.32 |
| Meilisearch検索 | 水 | 26 | 22.43 |
どうやら100件程度だとLIKE検索の方が速いようですね。おそらく、Meilisearchの方は単純な検索だけではなく外部HTTP API呼び出しのオーバーヘッドがあるためだと思います。小規模データだと純粋な検索時間よりもネットワーク往復コストの方が支配的になるため、Meilisearchの方が遅くなるようです。
それでは、件数を5万件程度に増やして再度検証してみます。
| 検索方法 | 検索キーワード | ヒット件数(件) | 検索時間(ms) |
|---|---|---|---|
| LIKE検索 | リチウム | 231 | 67.88 |
| LIKE検索 | 青い旗 | 405 | 59.12 |
| LIKE検索 | 水素 | 604 | 62.39 |
| Meilisearch検索 | リチウム | 231 | 10.72 |
| Meilisearch検索 | 青い旗 | 405 | 32.59 |
| Meilisearch検索 | 水素 | 604 | 31.22 |
ここまでいくと速度が逆転していますね。データ件数が多くなるほど、Meilisearch検索の真価が発揮されるようです。一方LIKE検索の方はやはりデータ件数が多くなるほど、線形に遅くなってしまっています。
Meilisearchの懸念点
色々と実験していく中で懸念点もありました。あくまで筆者の実験範囲内ですが、以下の点が気になりました。
- 全文検索ではよくあるタイポ補正機能(リチュウム→リチウムとして検索など)が日本語だと機能していなさそう
- フィールドごとの重み係数(Elasticsearch の boost: 3.0 相当)は存在しない
- 任意のスコアリング式(score = 0.7 * title_match + 0.3 * recency など)は書けない
実はタイポ補正機能自体はデフォルトで備わっているようですが、こと日本語においては実質対応されていなさそうです。また、他の検索エンジンに比べるとスコアリング調整の自由度はやや劣る印象がありました。
ちなみにMeilisearchのスコアリングはランキングルールという仕組みで管理されており、順序の入れ替えや追加はできますが、Elasticsearchのような任意の数式定義はできないようです。
デフォルトのランキングルールは以下です。(上から順に適用)
| ルール | 意味 |
|---|---|
| words | クエリ語をより多く含む結果を上位に |
| typo | タイポが少ないほど上位に |
| proximity | クエリ語同士が近いほど上位に |
| attribute | searchableAttributes の定義順で優先度付け |
| sort | 任意フィールドでのソート |
| exactness | 完全一致を部分一致より上位に |
また、フィールドの優先順位も書き換えることができます。例えば、今回の場合だとcontentよりもtitleヒットの優先度を上げるとかもできます。
これらを自由に組み合わせられるだけでも、一般的なサービスのスコアリング機能としては十分な気はしますね。
使ってみた感想
全体として、やはり導入が簡単な点が良いなという印象がありました。筆者はApache Solrの実装経験があるのですが、Solrだと大量のXMLファイルでスキーマやらなんやらを定義しておく必要があったので、それに比べるとずいぶんとシンプルで楽でした。
また、最近だとベクトル検索なんかも使いたい場合があると思いますが、こちらも対応しているようなので困ることはあまりないのではないかと思いました。
性能面も特に問題なさそうなので、ほとんどのプロジェクトはMeilisearchで十分なのではないかと思いました。
一方で、データ件数が数億規模であったり、スコアリングの調整をより自由度高く行いたい場合は他の検索エンジンを検討したほうがよさそうに思いました。
それでは、今回は以上としたいと思います。

コメントを投稿